
「平賀源内」と「GenAI」が交差した名前の由来から
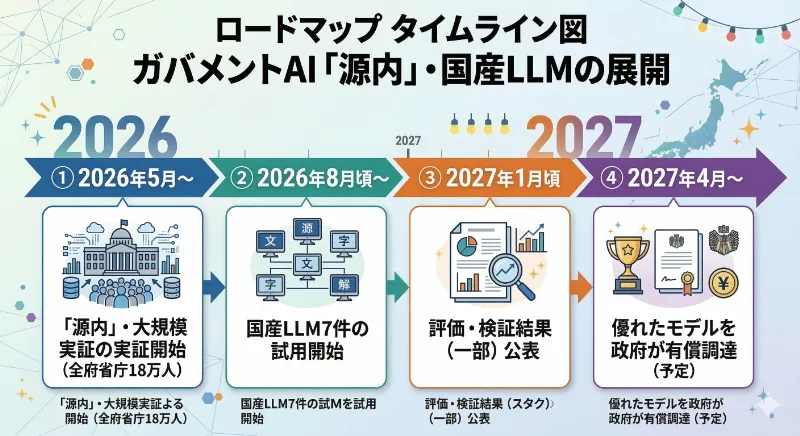
2026年3月6日、デジタル庁は二本の発表を同時に行った。一つは、全府省庁・外局等を含む39機関の政府職員約18万人を対象とした生成AI利用環境の大規模実証開始。もう一つは、その基盤で試用する国産大規模言語モデル(LLM)7件の選定結果だ。これは単なるAIツール導入のお知らせではなく、日本の行政がAI活用を”試行錯誤のフェーズ”から”省庁横断の実運用フェーズ”へと踏み出した宣言でもある。
その基盤となるシステムの名が「源内(げんない)」。デジタル庁が内製した生成AI利用環境に与えられたこの名には、ちょっとした遊び心が込められている。生成AIの英語表記「Generative AI」を略した「Gen AI(ゲンナイ)」の響きと、エレキテルや土用の丑など数多の発明・普及で江戸時代を驚かせた平賀源内の精神を掛け合わせたものだ。「様々な生成AIアプリケーションの発明が集まって欲しい」という願いが、この名前に込められている。デジタル庁のノートには「技術検証の意味合いが大きい」という率直な言葉もある。「源内」はサービスである前に、行政全体の生成AI活用における”共通ルールと標準化の実験場”として設計されたのだ。
なぜ今なのか──担い手不足という、避けられない現実
デジタル庁の発表資料と公式ノート記事を読むと、この大規模展開の背景として一貫して語られるのが少子高齢化による担い手不足という問題意識だ。デジタル庁でAIを担当する大杉直也氏は、公式noteでこう明言している。「人口減少と少子高齢化による担い手不足が深刻化する我が国において、公共サービスを維持・強化するためには、政府および地方公共団体の生成AIをはじめとするAIの積極的な利活用が不可避です」。
これは単なる効率化の話ではない。人事院のデータによれば国家公務員の一般職は約29万人、特別職を合わせれば59万人規模を擁するが、少子化による採用難が続く中、今の公共サービス水準を維持するには「一人ひとりの生産性を抜本的に上げる」しか選択肢がない。政府がここまでAI導入を急ぐのは、そういう構造的な危機感が根底にある。
加えて、今回の動きには「政府が率先してAIを使うことで、国産AIに需要の芯をつくる」という経済戦略上の意図もある。政府調達という巨大な需要を、国産モデルの育成・強化に充てることで、日本のAIエコシステム全体を底上げしようという発想だ。デジタル庁の公式発表では「民間投資の喚起」まで射程に入れた動きとして位置づけられている。
7つのモデル、それぞれの「素顔」
デジタル庁の発表によれば、2025年12月から始まった公募には15件が応募し、書類審査と評価テストを経て7件が選定された。なお「7人の侍」という呼称は報道各社が使った通称であり、デジタル庁の公式文書には一切登場しない点は注記しておく。
選ばれた7つのモデルは、規模も戦略も、そして「国産」の意味合いも一様ではない。
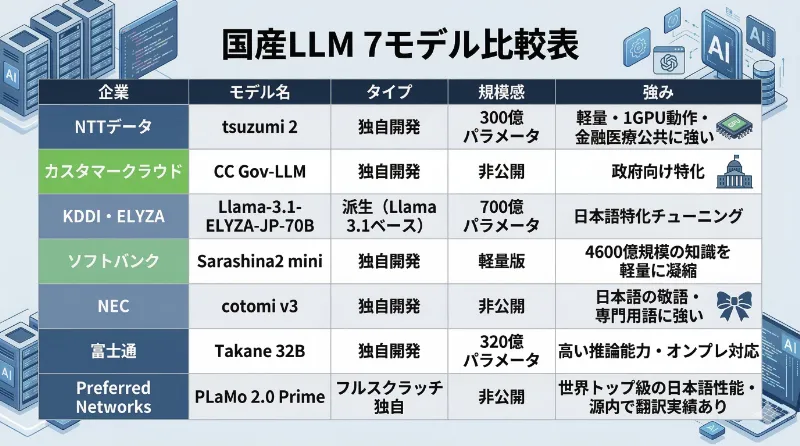
NTTデータの「tsuzumi 2」は、300億パラメータながら「GPU1基で動作する」軽量性が売りだ。金融・医療・公共分野の知識をあらかじめ強化しており、NTT公式サイトによれば企業・自治体のカスタマイズ用途を強く意識した設計になっている。国産LLMの中でも引き合いが旺盛で、リリース後に2000件超の問い合わせがあったとも報じられている。
ソフトバンク傘下のSB Intuitionsが開発した「Sarashina2 mini」は、4600億パラメータという国内最大級の規模を持つ基盤モデル「Sarashina」で培った知見を、扱いやすい軽量版に凝縮したモデルだ。大型モデルから「知識を移植する」という開発手法と、日本語の文化・慣習への深い理解が強みとされている。企業での導入しやすさを優先した設計が、行政の実運用環境にも適合すると評価されたのだろう。
Preferred Networksの「PLaMo 2.0 Prime」は、既存のオープンソースモデルに頼らず一から開発した「フルスクラッチ国産」モデルとして知られる。公式発表によれば日本語性能で世界トップクラスを誇り、実は今回の大規模展開より前から、源内に「PLaMo翻訳」として行政文書の高度な日本語翻訳機能として組み込まれていた。デジタル庁のリリースでも「行政文書に特有の日本語表現や記述様式への適合」が評価された旨が記されており、国産フルスクラッチモデルとしての存在感を示している。
一方で、KDDI・ELYZA共同応募体の「Llama-3.1-ELYZA-JP-70B」は、MeTaのオープンソースモデル「Llama-3.1-70B」をベースに、ELYZAが日本語追加事前学習と指示学習を施した700億パラメータのモデルだ。完全な独自開発ではないが、デジタル庁の選定基準第1項は「独自開発か派生かの区別等が具体的に説明可能であること」を求めており、透明な説明ができれば派生モデルも対象になる。実際にこのモデルは選ばれており、「素性が明確であること」の方が重要だと言える。
日本電気(NEC)の「cotomi v3」は日本語の敬語や専門用語の再現性に特化し、富士通の「Takane 32B」は高い推論能力とオンプレミス運用への対応を特徴とする。そしてカスタマークラウドの「CC Gov-LLM」は、大手の名前が並ぶ中で目を引く選定であり、同社のプレスリリースでは政府向けに独自開発したモデルとして紹介されている。
7件の顔ぶれを並べると、「国産AI」という言葉が指す範囲の広さがよく分かる。フルスクラッチの自社開発から、世界標準のオープンソースを日本語に最適化したものまで、アプローチは多様だ。しかし評価の軸は一本だ──「行政の現場で、実際に使えるか」。
9つの選定基準が静かに語ること
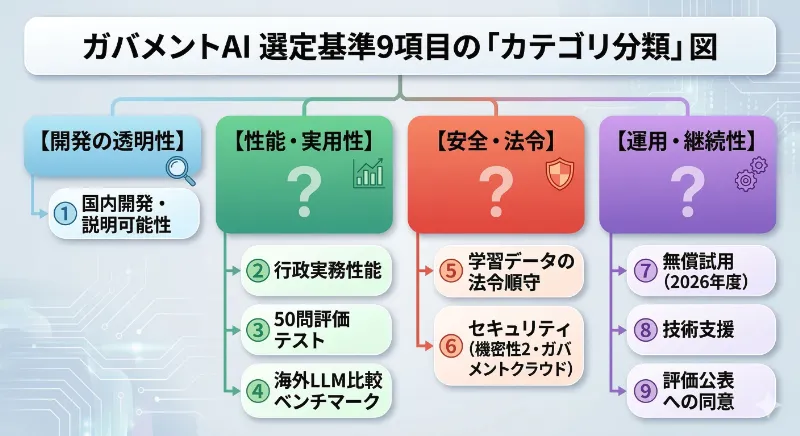
デジタル庁が公開した9つの選定基準は、表面上は「国産LLMを選ぶための審査項目」だが、読み解くと行政利用におけるAI選定の哲学が凝縮されている。
まず、性能だけでは受からない。「行政実務において実用可能な性能を有すること」という要件は当然としても、それと同等の重みで問われるのが「開発経緯・開発体制・独自開発か派生かの区別等が具体的に説明可能であること」という説明責任だ。AIがブラックボックスになりやすい時代に、行政利用では特に「何者が、どうやって作ったのかを説明できること」が実装要件の最前列に置かれている。
安全性の審査も独特だ。「デジタル庁が作成し、試験当日に初めて開示した50問の評価テスト」を受けさせるという設計は、事前の対策を防ぎ、モデルの真の能力を測ろうとする工夫だ。さらに海外主要LLMとの比較ベンチマーク結果の提出も求め、ハルシネーション・バイアス・差別的表現・有害コンテンツ生成への対策状況まで「説明可能な形」で審査している。性能と安全性を同じテーブルに乗せた審査体制は、行政利用の特性を如実に示している。
セキュリティ要件も明快だ。政府職員が「機密性2情報」を扱えるよう、ガバメントクラウド上の推論環境で動作することが必須条件として明記されている。クラウドサービスを海外事業者に全面依存しないためのインフラ整備と、AIの実運用が直結している。
そして費用面では、2026年度中は無償で試用できること──ただしガバメントクラウドと推論に係る費用はデジタル庁が負担する、という条件だ。政府側が場とコストを用意し、モデル提供側には「無償でも試用に耐える運用体制と技術支援」を求める。この対等でない非対称性の中に、「国産AIを育てる」という政策的意図が透けて見える。
2026〜2027:行政AI元年を刻むロードマップ

今後の流れはデジタル庁の公式発表に明確に示されている。まず2026年5月から、全府省庁の約18万人を対象に生成AI利用環境「源内」の大規模実証が始まる。法制度の調査・文書の要約と翻訳・国会答弁の作成支援など、デジタル庁が公開した資料では具体的なアプリケーション群が示されており、「とりあえず試してみる」段階はとっくに終わっている。
続いて2026年8月頃から、選定された国産LLMが源内に本格的に組み込まれて試用が始まる。2027年1月頃には評価・検証結果の一部が公表され、国産モデルの実力が社会に可視化される。そして2027年4月からは、実証で優れた成果を示したモデルを政府が有償で正式調達することが検討される。
この「試用→評価公表→調達」という流れの設計が持つ意味は大きい。政府が評価軸そのものを社会に提示することで、民間のAI導入側も、ベンダー側も、同じ「物差し」でAIの品質を議論できるようになる。行政の大規模調達は、日本のAI産業に対して「どんなモデルが合格水準か」を定義するという、市場への強力なシグナルでもある。
もう一つ重要なのが、各府省庁に求められる体制整備だ。デジタル庁の公式発表では、各府省庁に対して①職員への周知啓発と意識改革、②生成AI調達・利活用ガイドラインへの対応、③AI統括責任者(CAIO:Chief AI Officer)によるガバナンス・統括監理──の三点が明示されている。CAIOの設置義務化は2025年から議論が進んでおり、ITmediaの記事によれば2026年度以降の新規調達から原則適用される。AIを「情報システム部門の案件」として扱うのではなく、組織の意思決定レイヤーに責任者を置いて「業務改革の課題」として扱う──この順番の変化こそ、今回の動きの本質かもしれない。
国産AIとは「国籍」ではなく「説明責任の総体」

今回の動きを通じて、「国産AI」という言葉の定義が静かに更新されつつある。国内企業が開発したか否かという「国籍」の問題だけではなく、開発の透明性、学習データの法令順守、セキュリティ要件への適合、継続的な技術支援、評価への同意まで含めた「作り方・出し方・支え方」の総体として問われているのだ。
ソブリンAI(AI主権)という概念が国際的に注目を集めているのも、同じ問題意識から生まれている。自国のデータが、どの法律の下で、誰の管理のもとで処理されるかを把握することが、国家にとっても企業にとっても戦略上の要件になった時代に、デジタル庁の選定基準は「行政版ソブリンAIの定義」を実質的に示したと読むことができる。
中小企業への示唆──「18万人規模の実験」から読み解くAI導入の勝ち筋
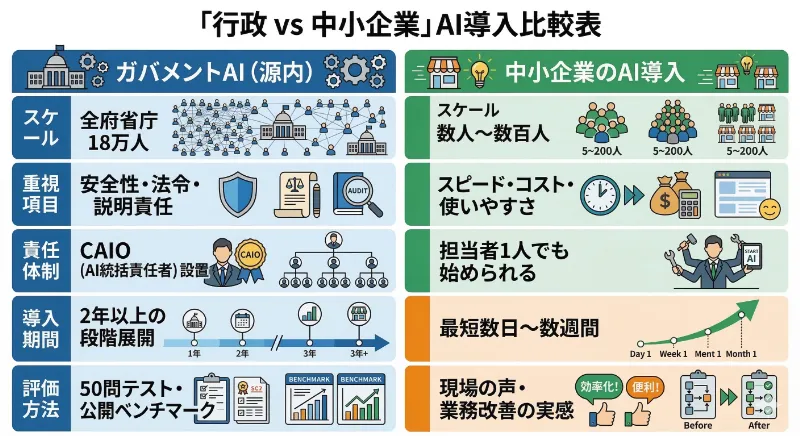
ここまで行政の話を読んできた方に、一度視点を変えてもらいたい。デジタル庁が行ったことは、スケールを除けば、企業のAI導入に置き換えられる話が多い。
第一に、AIは「導入するかしないか」ではなく「どう運用し、どう改善し、どう説明するか」が勝負になっている。9つの選定基準は、そのまま企業がAIベンダーを選ぶ際のチェックリストになりうる。性能だけでなく、安全性・法令・セキュリティ・支援・透明性まで含めて評価する文化が、行政に先行して定着しつつある。
第二に、「単にツールを入れる」だけでは変わらないという認識だ。デジタル庁の発表資料には「業務プロセス・働き方・組織文化の抜本的な変革を伴うことが重要」と明記されている。これは行政に限った話ではない。AIを入れる前に、責任者とルールと教育の仕組みを先に整備する──この順番が成否を分ける。
第三に、小さく始めつつ、全体展開を前提に設計することの重要性だ。行政は「試用→評価→一部公表→調達検討」という段階設計を丁寧に行っている。企業でも、PoC(概念実証)を繰り返すだけで全社展開に踏み出せない「PoCの墓場」は珍しくない。評価の仕組みとガバナンスを先に置き、全体展開を前提に考えることが、AI投資を成果に変える道筋だ。
中小企業のAIだって、侮れない──AIスミズミという選択肢
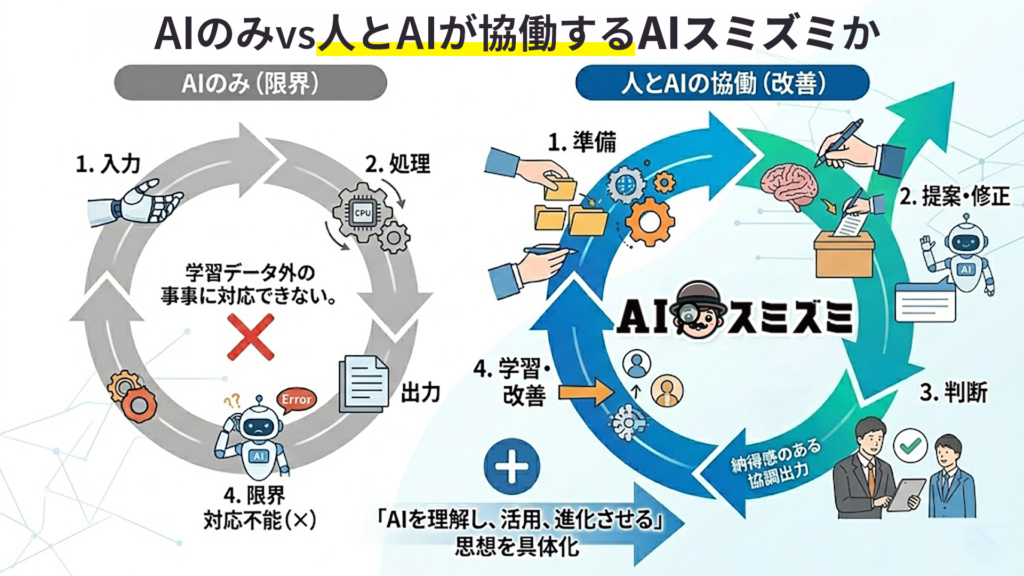
国が進める18万人規模のガバメントAIは、日本のAI水準の底上げを狙う壮大な実験だ。しかし現場のスピードという点では、大組織より中小企業の方がずっと速く動けることも多い。
弊社デジタルレクリムが提供するAIスミズミは、そういう「中小企業の現場サイズ」に特化したAIチャットボット構築支援サービスだ。ヒアリングと資料提供をもとに、AIチャットボットの構築を完全代行し、最短6営業日での実装を実現している。ITに詳しくなくても進められる設計を前面に出しているのが特徴で、テキスト生成にとどまらず、画像の自動表示やYouTube動画との連携など、「見せて伝える」導線まで含めて設計できる。
BtoCの現場では、AI自体の精度以上に「顧客との接触面をどう設計するか」が成果を左右する。その点でAIスミズミは、LINE公式アカウントとの連携オプションも持っており、すでに顧客接点が確立している事業者が既存の導線を活かしてAIを使えるようになっている。
国が「安全性・説明責任・セキュリティ」を問い続けるガバメントAIの文脈と並行して、企業の現場では「導入スピード・運用の丸投げ可否・集客導線まで作り切れるか」が問われ続けている。両者の問いは別物ではなく、本質は同じ──AIが現場の役に立つかどうかだ。
行政がAI活用の”本格実運用フェーズ”へ踏み込んだ今、中小企業にとっても「試行」を卒業して「現場実装」へ進む好機が来ている。
AIスミズミの詳細はこちら → https://www.digital-reclame.co.jp/lp/sumizumi/
参考(一次情報源)
- デジタル庁:全府省庁の約18万人の政府職員を対象としたガバメントAI(源内)の大規模実証を開始します
- デジタル庁:ガバメントAIで試用する国内大規模言語モデル(LLM)の公募結果
- デジタル庁note:ガバメントAI、プロジェクト「源内」の構想紹介
- ELYZA公式プレスリリース(PR Times):Llama-3.1-ELYZA-JP-70Bの開発について
- Preferred Networks:PLaMo 2.0 Prime リリース・日経優秀製品賞
- NTTデータ:tsuzumi 2 製品ページ

コメント