「ChatGPTは便利だけど、ウチの社内ルールとか製品マニュアル、当然ながら答えてくれない」——AI活用に踏み込んだ企業が、ほぼ100%ぶつかる壁です。自社のドキュメントをまるっと読み込ませて、社内Q&AボットからRFPの下書きまで自動で叩き出してくれる「社内ナレッジAI」が欲しい。けれど、いざ社内のSEに頼むと「いや、それ大改造ですよ」と渋い顔をされる。あるある、ですよね。
この袋小路を、ノーコードで一気にぶち破れるのが Dify(ディフィ)の RAG 機能です。PDFをドラッグ&ドロップ、Notionをポチッと連携、Webサイトを丸ごと吸い込む——それだけで「ウチの会社のことを知ってるAI」が組み上がります。本記事は、2026年5月時点の最新版 Dify を前提に、RAGの基本から構築手順、精度を上げるためのチャンク戦略、運用で確実にハマる失敗パターン、ビジネス活用事例、そして「内製 vs 外注」の判断軸まで、ぜんぶ一気に解説していきます。読み終わるころには、月曜の朝イチで「ちょっと社内ナレッジAI、作ってみましょうか」と提案できる解像度になっているはずです。
そもそも RAG って何? 5分で輪郭をつかむ
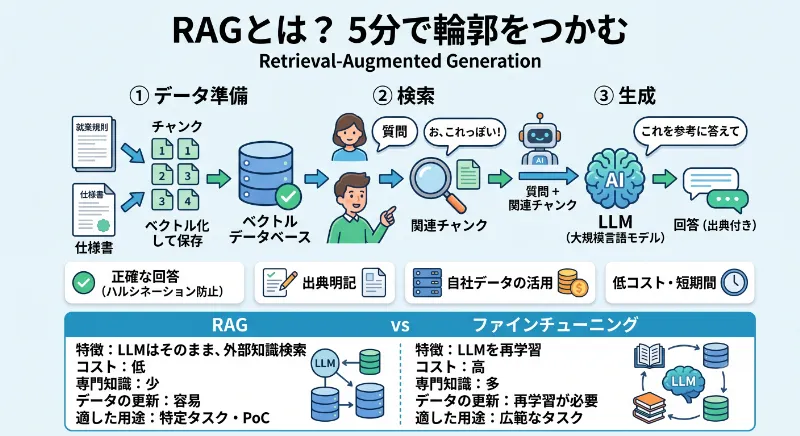
RAG(ラグ)は Retrieval-Augmented Generation の略で、日本語に意訳すると「外部の知識を引っ張ってきて答える生成AI」のこと。普通のChatGPTは「学習時に世の中にあった情報」しか知りませんが、RAGを使えば、自社の就業規則・製品仕様書・FAQ・議事録といった社外秘のドキュメントを”その場で参照しながら”回答させられます。
仕組みをざっくり言うと、こんな3ステップです。まず①社内ドキュメントを「チャンク」と呼ばれる小さな塊に分割してベクトル化(数値化)し、データベースに保管します。次に②ユーザーが質問を投げると、その質問と意味的に近いチャンクを「お、これっぽい!」と検索エンジンが拾ってきます。最後に③拾ってきたチャンクをLLM(大規模言語モデル)に「これを参考に答えて」と渡し、人間に読みやすい文章として返す——という流れ。ハルシネーション(AIのデタラメ回答)を防げて、出典も提示できる。「マイAI百科事典」を作るような感覚ですね。
RAGと、よく比較される手法に「ファインチューニング」があります。こちらはLLMそのものを追加学習させるアプローチで、汎用性は高い反面、コスト・時間・専門知識のハードルが恐ろしく高い。一方RAGは 「LLMはそのままに、知識だけ後付けで足す」 方式。社内ドキュメントが頻繁にアップデートされる中小企業や、PoC段階の検証には圧倒的にRAGの方が向いています。RAGとファインチューニングの違いについてはAWS公式の解説も分かりやすいので、合わせて読むと理解が深まります。
なぜ今「Dify × RAG」が熱いのか

RAGを実装する方法は、実は山ほどあります。LangChain や LlamaIndex でゴリゴリPythonを書く、Azure OpenAI Service の「Add your data」で組む、専用SaaSを買う——どれもアリです。ではなぜ Dify がここにきて急浮上しているのか。理由は身も蓋もなく、「ノーコードでここまで出来るのは反則レベル」だからです。
2024年に上陸して以来、Difyは「ChatGPTの会社版が30分で作れる」と話題になり、2026年現在では大企業のPoCから個人開発まで広く採用されています。GitHubのスター数は10万を突破し、コミュニティ拡大スピードもオープンソースAIプラットフォームの中ではトップクラス。日本語UIも公式対応済みで、社内導入の心理的ハードルがほぼゼロ、というのも大きいですね。
そしてDifyの真骨頂は、「RAG」「ワークフロー」「エージェント」「複数LLMの切り替え」「アプリ公開」までが1つの画面で完結していること。RAGだけ別ツール、UIだけ別ツール……みたいな”ツールパッチワーク地獄”から解放されるわけです。Difyそのものの概要は Dify(ディフィ)とは?ChatGPTとの違い・できること・料金をわかりやすく解説 でも詳しく扱っているので、まずDifyに不慣れな方はそちらから読むことをおすすめします。
DifyのRAG機能、何がどこまで出来るのか
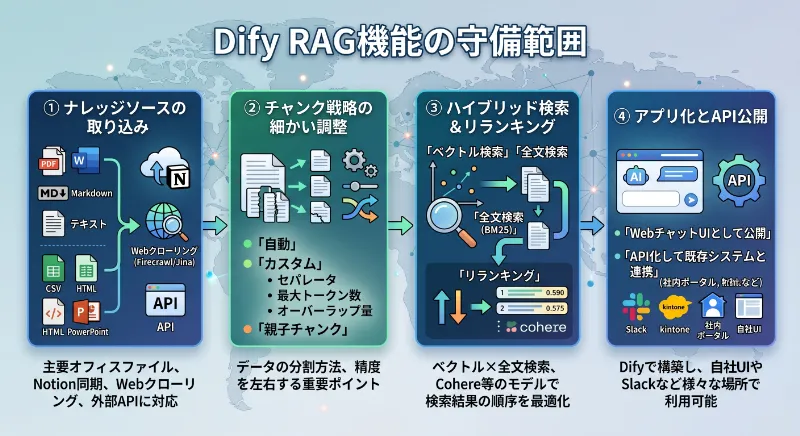
「RAGに対応してます」と謳うサービスは多いですが、Difyが提供するRAG周りの守備範囲は、率直に言って広いです。ざっくり整理すると、次の4ブロックを丸ごとカバーします。
① ナレッジソースの取り込み
取り込めるデータの種類が豊富で、PDF、Word、Markdown、テキスト、CSV、HTML、PowerPoint といった主要オフィスファイルはほぼ全部対応。さらに Notion との同期、Webサイトのクローリング(Firecrawl/Jina経由)、外部APIからのインポートにも対応しています。「Notionで社内ナレッジを溜めてる」「業界情報サイトを毎週チェックしてる」みたいなチームは、ほぼ無加工で取り込めるはず。
② チャンク戦略の細かい調整
Difyでは、取り込んだドキュメントをどう分割するかを「自動」「カスタム」「親子チャンク」の3モードから選べます。さらに、セパレータ(区切り文字)、最大トークン数、オーバーラップ(重なり)量まで手で触れる。「RAGの精度はチャンク戦略で7割決まる」 と言っていいくらい、ここは重要ポイント。後ほど精度UP戦略の章でガッツリ深掘りします。
③ ハイブリッド検索 & リランキング
Difyは「ベクトル検索」と「全文検索(BM25系)」を同時に走らせるハイブリッド検索に対応しています。さらにCohereや独自のリランキングモデルを噛ませて、検索結果の順序を最適化することも可能。「ベクトル検索だけだと意味は近いけど狙ったページが出てこない」問題を、ハイブリッド+リランクで一気に解決できる仕様です。
④ アプリ化とAPI公開
作ったRAGは、その場でWebチャットUIとして公開できますし、API化して既存システム(社内ポータル、Slack、kintone、自社サイトのチャットウィジェット)から呼び出すこともOK。「Difyで作って、見せる場所は別の自社UI」みたいな構成も普通に組めます。Difyの全体的な使い方の流れは Difyの使い方を完全解説!ノーコードでAIチャットボットを作る方法 で図解しているので、UI周りのイメージを掴みたい人はチェックを。
【実践】DifyでRAGを構築する5ステップ
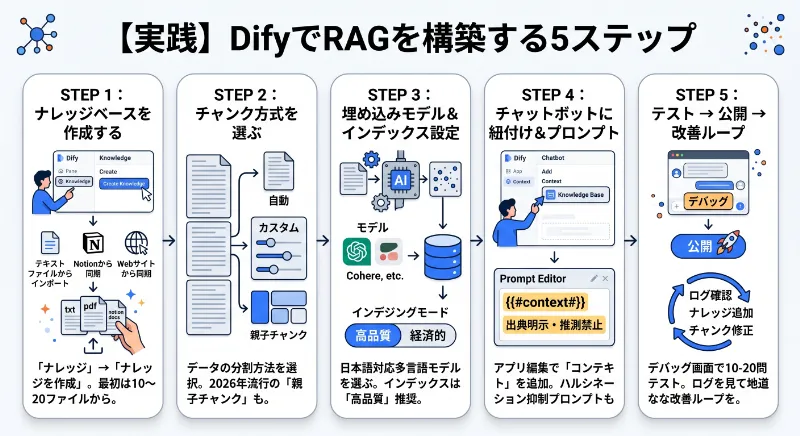
ここからは、実際にDifyでRAGアプリを組むときの流れを5ステップで追います。前提としてDifyのアカウントは作成済み(クラウド版は 公式サイト から無料登録できます)、LLMのAPIキー(OpenAI、Anthropic、Google AIなど)も登録済みとします。
STEP1:ナレッジベースを作成する
左ペインの「ナレッジ」→「ナレッジを作成」を選択。データソースは「テキストファイルからインポート」「Notionから同期」「Webサイトから同期」の3つから選びます。社内ドキュメントを使うなら基本はテキストファイルからのインポートでOK。1ファイル15MBまで、合計100ファイルまでアップロードできます(プランによって上限は変動)。最初は10〜20ファイル程度の小さなナレッジから始めるのがコツ。いきなり500ファイル放り込んで「動きません!」と嘆くのは、RAG初心者あるあるです。
STEP2:チャンク方式を選ぶ
アップロード後、「テキストの前処理とクリーニング」画面で、チャンク方式を指定します。「自動」 はDifyがよしなに分割してくれる楽ちんモードで、PoC段階ならこれで充分。「カスタム」は最大トークン数(500前後が無難)、セパレータ(\n\nや「。」など)、オーバーラップ(50前後)を手で指定するモード。マニュアル類のように章立てがしっかりしているドキュメントなら、こちらの方が精度が出ます。「親子チャンク」 は2026年で大流行している手法で、検索用の小さな子チャンクと、生成用の大きな親チャンクを別建てで持つやり方。長文ドキュメントが多い企業はぜひ試してください。
STEP3:埋め込みモデルとインデックスモードを設定
埋め込み(Embedding)モデルは、テキストをベクトル化するためのモデル。OpenAIの text-embedding-3-large、Cohereの embed-multilingual-v3.0、ローカルなら multilingual-e5-large あたりが定番。日本語ドキュメントが中心なら、多言語対応モデルを選ぶこと。ここを英語特化モデルにすると、日本語の意味理解で詰まります。インデックスモードは「高品質」を推奨。「経済的」モードはコストは安いですが、精度が体感で20〜30%落ちます。
STEP4:チャットボット(またはワークフロー)に紐付け
「スタジオ」→「アプリを作成」→「チャットボット」または「チャットフロー」を選択。アプリの編集画面で「コンテキスト」エリアにSTEP1〜3で作ったナレッジベースを追加すれば、紐付け完了。プロンプトには {{#context#}} 変数を入れ、「以下のコンテキストを参考に、なるべく出典を明示しながら回答してください。コンテキストに無い情報は推測せず『資料に記載がありません』と答えてください」のようなハルシネーション抑制プロンプトを必ず入れます。
STEP5:テスト → 公開 → 改善ループ
右側のデバッグ画面で、想定される質問を10〜20個投げてみて、回答の精度・出典の正しさ・トーンをチェック。期待通りなら「公開」ボタンで公開、WebチャットURL or APIキーを発行できます。RAGは「作って終わり」ではなく「作ってからが本番」。ログを見て、ユーザーの実際の質問パターンを観察し、不足しているドキュメントを足したり、チャンク分割を変えたりして、地道に精度を上げていく改善ループが命です。
RAG精度を爆上げするチャンク戦略・5つの鉄則
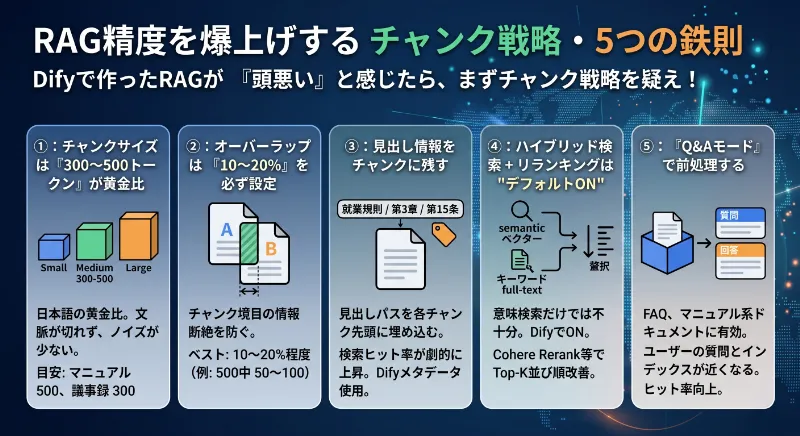
「Difyで作ったRAGがどうも頭悪い」と感じたら、まず疑うべきはLLM ではなくチャンク戦略です。ここでは2026年時点でRAG実装の現場でほぼ確立してきた「効くノウハウ」を5つ凝縮してお届けします。
鉄則①:チャンクサイズは「300〜500トークン」が黄金比
小さすぎる(100以下)と文脈が切れて意味不明になり、大きすぎる(1000以上)と検索ノイズが増えて精度が落ちます。日本語の場合、300〜500トークンが多くのケースで一番ハマる。マニュアルや規程のような構造化された文書なら500、議事録やメモなど雑多な文書なら300が目安です。
鉄則②:オーバーラップは「10〜20%」を必ず設定
オーバーラップとは、隣り合うチャンクで「ちょっとずつ重ねる」設定のこと。これをゼロにすると、章の境目で情報がブツ切りになり、肝心の質問にヒットしなくなります。チャンクサイズの10〜20%程度(500なら50〜100)が経験則上ベスト。
鉄則③:見出し情報をチャンクに残す
「就業規則 / 第3章 服務 / 第15条 服装」みたいな見出しパスを各チャンクの先頭に埋め込むと、検索ヒット率が劇的に上がります。Difyの「メタデータ」機能を使えば、ファイル単位でこの情報をくっつけられます。ちょっと手間ですが、見出し付与はRAGの精度を底上げする神テクニック。
鉄則④:ハイブリッド検索 + リランキングは”デフォルトON”
ベクトル検索だけだと「意味は似てるけど狙いとは違う章」を引いてくることがあります。Difyのナレッジ設定で「ハイブリッド検索」をオンにし、さらに Cohere Rerank などのリランキングモデルを噛ませると、Top-Kの並び順が圧倒的に改善します。特に日本語の固有名詞や型番が絡む検索では効果絶大。
鉄則⑤:「Q&Aモード」で前処理する
Difyにはドキュメントを自動でQ&A形式に変換してくれる「Q&Aモード」があります。FAQやマニュアル系のドキュメントは、Q&Aモードで前処理しておくと、ユーザーの質問とインデックスの”質問”がベクトル空間で近くなり、ヒット率が顕著に上がります。前処理に若干の時間とコストがかかりますが、コールセンター系のRAGならほぼ必須レベル。
「Dify × RAG」失敗パターンあるある6選

ここからはちょっとシビアな話。実際にDifyでRAGを組んでみた企業から相談を受ける中で、頻出する「やらかしパターン」を6つ紹介します。事前に知っておけば、確実に回避できる地雷です。
- ① いきなり全社ドキュメントを投入:500ファイル一気にアップ → ノイズだらけで精度激減。最初は20ファイルから始めて、徐々に増やす。
- ② チャンクサイズを変えずに自動任せ:マニュアル系で300トークンのまま運用 → 文脈が切れて回答が薄い。文書タイプごとにチャンクサイズを調整する。
- ③ 埋め込みモデルが英語特化:日本語の意味理解が浅く、的外れな検索結果が並ぶ。必ず多言語対応モデルを選ぶ。
- ④ ハルシネーション抑制プロンプトを書かない:「資料に書いてないことも、それっぽく答える」事案が多発。「コンテキスト外は『記載なし』と答える」と明示する。
- ⑤ ドキュメントが古いまま放置:1年前の就業規則を回答 → 大事故。月1回はナレッジを更新するルール作りを。
- ⑥ アクセス権限を設定しない:機密情報まで全社員が引き出せる状態に。Difyの「メンバー権限」「アプリ公開範囲」を必ず確認する。
ビジネスでの活用事例:何に効くのか

RAGの効果が一番出やすいのは、「過去資料を見れば答えがあるはずなのに、人が読み込むのが面倒くさい」業務です。具体的に、業種別に効きどころを整理してみます。
医療・クリニック領域
診療科の問い合わせ対応、料金・キャンペーン案内、施術内容の説明をRAG化すると、受付業務が大幅に軽減できます。ホワイトニングや美容領域のような自由診療では、メニューが頻繁に変わるため、「ナレッジを更新するだけで全チャネルの回答も同期される」RAG構成と相性抜群。実際の導入文脈は AIスミズミ でも詳しく解説しています。
士業・コンサル
過去の判例・契約書テンプレ・規定集を社内RAGに集約することで、新人弁理士・社労士の調査時間が劇的に減ります。法改正の頻度が高い分野は、ドキュメント更新フローも合わせて整備するのが鉄則。
製造業・小売
製品マニュアル、トラブルシューティング、SDS(安全データシート)などをRAG化すれば、現場の作業員がスマホから即座に質問可能。コールセンターの一次受けをRAGに任せ、複雑な案件だけ人間にエスカレーションする構成が最近のスタンダードです。
社内ヘルプデスク
「経費精算の締め日いつだっけ」「VPN接続できないんだけど」みたいな、いわゆる“情シス・総務あるある質問”をRAGに丸ごと吸わせると、バックオフィス部門の負担が体感で半分以下に。社内ナレッジの「常駐コンサル」を、Difyで安価に常時稼働させるイメージですね。AIによる業務効率化全般のロードマップは AI業務効率化記事 も参考になります。
気になる!RAG運用にかかる「お金」の話

「これってトータルでいくらかかるの?」という根本的な疑問にも答えておきます。Dify自体のコストと、LLM・埋め込みモデルの利用コストを分けて考えるのがポイントです。
Dify本体(クラウド版)は無料プランから始められ、Professionalプラン(月額59ドル)、Teamプラン(月額159ドル)と段階的に拡張できます。セルフホスト版は完全無料で、自社サーバーで動かしたい企業はこちらを選びがち(その代わりインフラ・運用は自前)。LLM/EmbeddingコストはOpenAI・Anthropic・Google AI などへ実費課金。OpenAI公式の料金表 を見ると、GPT-4o系で 100万トークンあたり数ドル〜十数ドルの世界。月間1万メッセージ程度のRAGアプリなら、LLMコストはだいたい月1〜3万円が目安です。
「思ったより安い」と感じる方が多いはず。ただし、これは「自分たちで運用できれば」の話。設計ミスでLLMコストが想定の5倍に跳ね上がった、ナレッジ更新フローが整っておらず誰も触らなくなった、リランキングが効きすぎてレスポンスが遅い、みたいなトラップは普通にあります。コストを抑えつつ精度を担保するなら、初回設計だけはプロに任せて、運用は内製化するハイブリッド型が一番コスパが良い、というのが現場の肌感覚です。
「自社でやるか、プロに頼むか」判断フローチャート
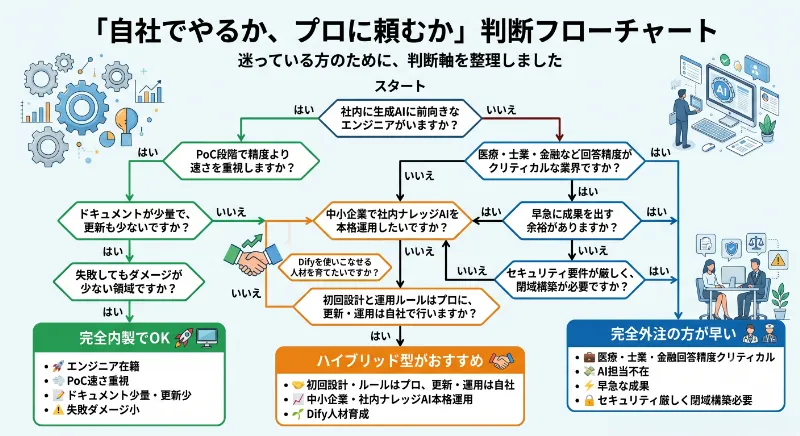
ここまで読んで「ウチはどっちで進めるべき?」と迷っている方のために、判断軸を整理しておきます。
- 完全内製でOK:社内に生成AIに前向きなエンジニアがいる/PoC段階で精度より速さを重視/ドキュメントが少量で更新も少ない/失敗してもダメージが少ない領域
- ハイブリッド型がおすすめ:初回設計と運用ルール作りはプロに、日々の更新と運用は自社で/中小企業で社内ナレッジAIを本格運用したい/Difyを使いこなせる人材を社内に育てたい
- 完全外注の方が早い:医療・士業・金融のように回答精度がクリティカル/社内にAI担当を置く余裕がない/早急に成果を出したい/セキュリティ要件が厳しく自社環境への閉域構築が必要
デジタルレクリムの「AIスミズミ」は、まさにこの「初回はガッツリ設計を支援し、運用はお客様側で回せるよう伴走」というハイブリッド型に最適化されたサービスです。「とりあえずDifyを触ってみたけど、社内ナレッジAIをちゃんと業務に組み込むなら、設計だけプロに見てもらいたい」というご相談、月に数件いただいています。診断と要件整理だけのライト相談も受けていますので、お気軽にどうぞ。
セキュリティと運用ガバナンスで押さえるべきこと

RAGは「社内ドキュメントをAIに食べさせる」仕組みなので、セキュリティとガバナンスの設計を最初に決めないと、後で大事故になります。最低限押さえておきたいのは次の3点です。
まずデータ取り扱いポリシー。クラウド版Difyを使うなら、ドキュメントは海外のサーバーに保存される前提です。機微情報を扱う場合は、Difyのセルフホスト版を自社環境にデプロイする方が安全。LLMもAzure OpenAIの日本リージョン or Anthropicの日本リージョンを使うなど、データ越境のコントロールを設計しましょう。経産省・総務省が公開しているDX関連ガイドラインでも、生成AI利用時のデータガバナンスは強く言及されています。
次にアクセス制御。Difyの「メンバー権限」「アプリの公開範囲」「APIキーの管理」を、人事ローテーションに合わせて運用するルールを決めておくこと。退職者のAPIキーがそのまま放置、というのが地味に多い事故パターンです。最後に監査ログ。誰がどんな質問を投げ、AIがどんな回答を返したか、最低でも90日分は保管しておきましょう。トラブル時の原因究明にも、コンプライアンス対応にも必須です。
2026年の最新トレンド:RAGの次に来るもの

最後にちょっと未来の話。2026年に入って、RAGの世界は「単純な検索拡張」から一歩進み、エージェント型RAGや GraphRAGへと進化しています。エージェント型RAGは、AIが自分で「どの情報源をどう検索すべきか」を判断し、必要に応じて複数のナレッジベース・API・ツールを使い分けるアプローチ。GraphRAGは、ドキュメント間の関係性をグラフ構造でモデル化することで、より深い文脈理解を可能にする手法です。
Difyはこの両方に対応するアップデートを段階的にリリースしており、特に「ワークフロー機能 × ナレッジ × ツール呼び出し」を組み合わせたエージェント型RAGは、ノーコードで構築できる土台が既に整っています。チャットボットの未来像については、チャットボットとAIチャットボットの違い記事や、AIチャットボットおすすめ25選 も合わせて読んでおくと、「今後どこに張るべきか」の解像度が一気に上がるはずです。
まとめ:明日から動くなら、まずは1ドキュメントから

ここまで読んでいただきありがとうございました。長い記事になりましたが、要するに言いたいことは1つで、「社内ナレッジAIを作るなら、2026年の今、Dify×RAGが一番コスパが良い」。これに尽きます。ノーコードで始められ、必要に応じてプロのセオリーを後から取り入れていける柔軟性こそ、Difyの最大の魅力です。
もし「とりあえず社内のFAQドキュメント1本だけでもRAG化してみたい」「Difyの初期設計だけプロにレビューしてほしい」「医療や士業のような高精度を求められる業界で、ちゃんと運用に乗せたい」という温度感があれば、お気軽にデジタルレクリムへご相談ください。AIサービス一覧から、自社の課題に合うソリューションを見つけられますし、「AIスミズミ」は中小企業のための初期設計支援・伴走運用に特化したサービスです。お問い合わせからは具体的なご相談も受け付けています。
RAGの世界はまだ進化の途中ですが、確実に言えるのは「動かしたチームから知見が貯まる」ということ。読んだだけで止まらず、ぜひ1ドキュメントでいいので、Difyに放り込んでみてください。月曜の朝、コーヒーを飲みながらナレッジAIに「先週の議事録の決定事項まとめて」と投げ、3秒で返ってきた回答を見たとき——「あ、これが2026年の働き方か」と腹落ちするはずです。


コメント