
RAGとは?「AIが嘘をつく問題」を解決する革命的テクノロジーをわかりやすく解説
「ChatGPTに会社のことを聞いたら、まったくデタラメな回答が返ってきた…」
こんな経験、ありませんか? 生成AIって確かにすごいんだけど、知らないことも知ったかぶりで答えちゃうのが最大の弱点なんですよね。専門家っぽい顔して堂々とウソをつく。いわゆる「ハルシネーション」ってやつです。
で、この問題を根本から解決するのがRAG(Retrieval-Augmented Generation:検索拡張生成)という技術。2024年後半あたりから企業のAI導入で「とりあえずRAG」が合言葉になりつつあるほど、いま最もアツいAI技術のひとつです。
この記事では、RAGの仕組みから実際の活用事例、導入メリット・デメリット、そして2026年の最新トレンドまで、IT担当者じゃなくても理解できるレベルでまるっと解説します。
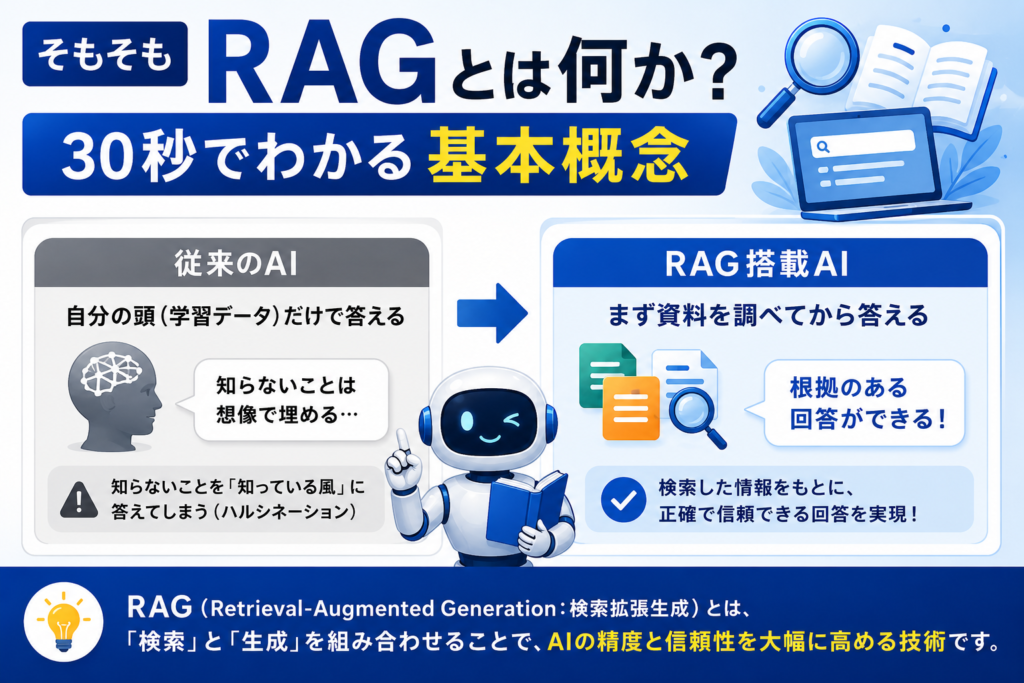
そもそもRAGとは何か?30秒でわかる基本概念
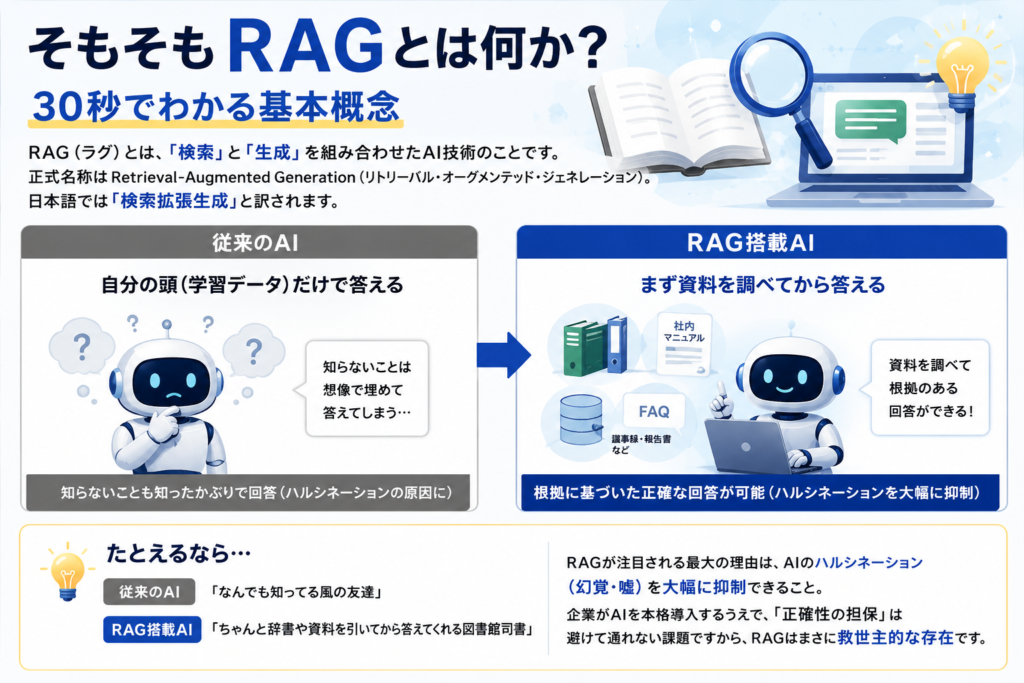
RAG(ラグ)とは、「検索」と「生成」を組み合わせたAI技術のことです。正式名称はRetrieval-Augmented Generation(リトリーバル・オーグメンテッド・ジェネレーション)。日本語では「検索拡張生成」と訳されます。この技術は2020年にMeta(旧Facebook)の研究チームが発表した論文で提唱され、その後急速に普及しました。
ものすごくザックリ言うと、こういうことです。
従来のAI:「自分の頭(学習データ)だけで答える」→ 知らないことは想像で埋める
RAG搭載AI:「まず資料を調べてから答える」→ 根拠のある回答ができる
たとえるなら、従来のAIは「なんでも知ってる風の友達」。RAGは「ちゃんと辞書や資料を引いてから答えてくれる図書館司書」みたいなものです。
この技術が注目される最大の理由は、AIのハルシネーション(幻覚・嘘)を大幅に抑制できること。企業がAIを本格導入するうえで、「正確性の担保」は避けて通れない課題ですから、RAGはまさに救世主的な存在なんです。
RAGの仕組み|3ステップで理解する動作フロー
RAGの動作は、大きく3つのステップで構成されています。技術的に深い話は省いて、イメージで理解しましょう。
ステップ1:質問の「意味」をベクトル化する
ユーザーが質問を入力すると、AIはまずその質問文を「ベクトル」と呼ばれる数値データに変換します。これは人間の言葉をコンピューターが理解できる形に翻訳する作業です。
「今月の売上目標はいくら?」という質問が、[0.23, 0.87, 0.45, …]のような数値の羅列に変わるイメージですね。この処理を「エンベディング(Embedding)」と呼びます。
ステップ2:関連する情報を「検索」する
次に、変換されたベクトルを使って、あらかじめ用意しておいたベクトルデータベースから関連性の高い情報を検索します。
ここがRAGの肝。社内マニュアル、FAQ、議事録、商品カタログなど、あなたの会社の情報をデータベースに格納しておけば、AIはそこから「使える情報」を引っ張ってくるわけです。
ステップ3:検索結果をもとに「回答を生成」する
最後に、検索で見つかった情報をコンテキスト(文脈)としてLLM(大規模言語モデル)に渡し、それを踏まえた回答を生成します。
つまりAIは、「自分の知識+今回検索して見つけた情報」の両方を使って答えるので、的外れな回答が激減するわけです。しかも回答の根拠(ソース)も明示できるので、「なんでその答えなの?」にも対応できます。
RAGが解決する3つの課題|なぜ企業に必要なのか
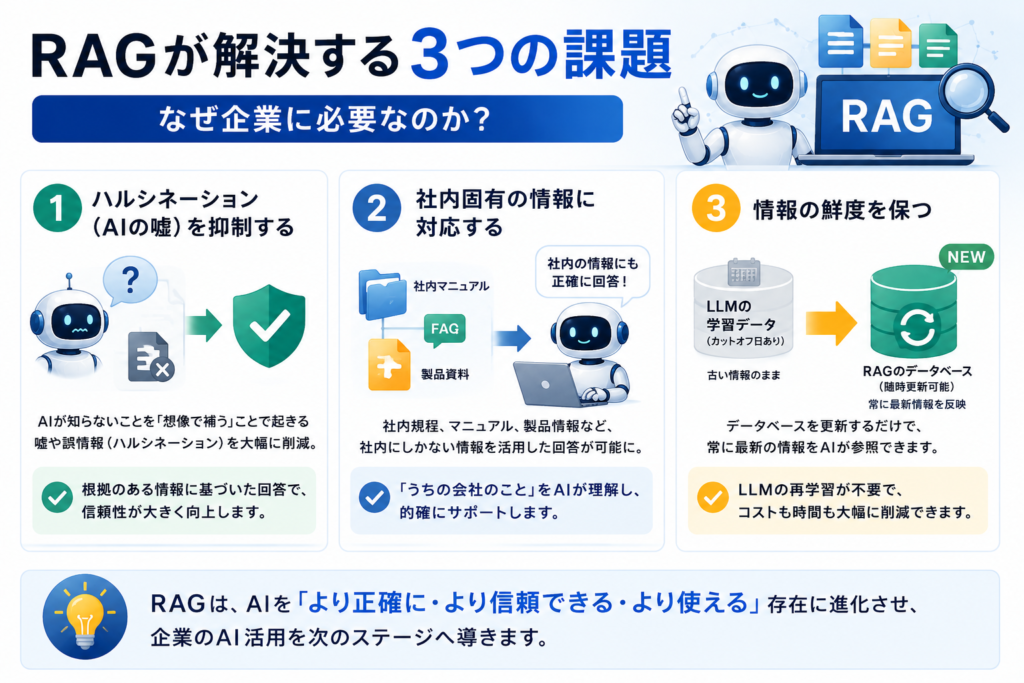
課題1:ハルシネーション(AIの嘘)を抑制する
生成AIの最大の問題点であるハルシネーション。存在しない論文を引用したり、架空の法律を持ち出したり。ビジネスの現場でこれが起きると、最悪の場合は損害賠償問題にもなりかねません。
RAGを導入することで、AIは検索で見つけた実際のデータに基づいて回答するため、「知らないことを想像で補う」場面が大幅に減ります。完全にゼロにはなりませんが、体感で80〜90%はハルシネーションが改善されるケースが多いです。
課題2:社内固有の情報に対応する
ChatGPTやGeminiなどの汎用AIは、インターネット上の公開情報をベースに学習しています。つまり、あなたの会社の社内規程、顧客データ、製品マニュアルといった非公開情報は一切知りません。
RAGなら、これらの社内ドキュメントをベクトルデータベースに格納することで、「うちの会社の有給休暇は何日?」「この製品のスペックは?」といった質問にも的確に答えられるようになります。
課題3:情報の鮮度を保つ
LLMの学習データには「カットオフ日」があります。たとえばGPT-4oの学習データは2024年10月まで。それ以降の情報は原則として知りません。
一方、RAGのデータベースは随時更新が可能です。新しい社内通達、最新の製品情報、今朝の議事録──これらをデータベースに追加するだけで、AIはすぐに最新情報を踏まえた回答ができるようになります。LLMの再学習(ファインチューニング)と違って、コストも時間もほとんどかかりません。
RAGとファインチューニングの違い|どちらを選ぶべきか

「AIをカスタマイズするならファインチューニングがあるじゃん」と思った方。鋭いですね。でも、RAGとファインチューニングは役割が全然違います。
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| 目的 | 外部知識の参照・最新情報の反映 | モデルの振る舞いや文体の変更 |
| コスト | 低〜中(DB構築費用のみ) | 高(GPU計算コスト大) |
| 更新の手軽さ | ◎(ドキュメント追加のみ) | △(再学習が必要) |
| ハルシネーション対策 | ◎(根拠ベースの回答) | △(根本的解決にならない) |
| 向いている用途 | FAQ、社内検索、カスタマーサポート | 特定業界の専門用語対応、文体統一 |
結論からいうと、多くの企業ユースケースではRAGが最適解です。ファインチューニングが必要になるのは、AIの「話し方」や「専門知識の深さ」を根本的に変えたい場合に限られます。両者を組み合わせる「RAG+ファインチューニング」という上級アプローチもありますが、まずはRAGから始めるのが王道です。
RAGの活用事例5選|実際にどう使われているのか
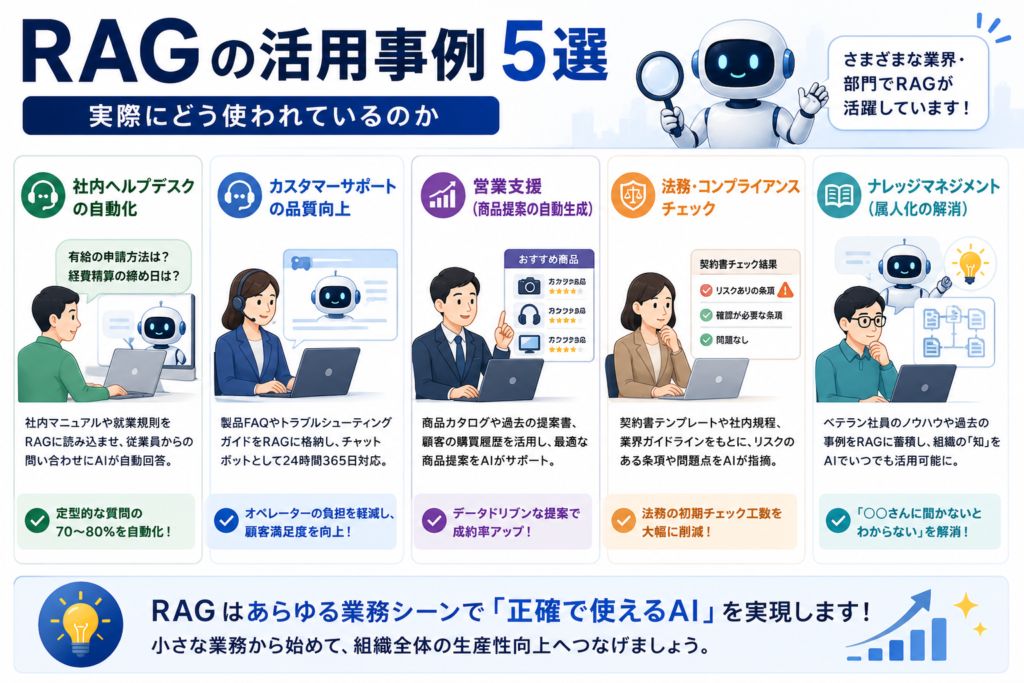
事例1:社内ヘルプデスクの自動化
最も導入ハードルが低く、効果が出やすいのがこのパターン。社内マニュアルや就業規則をRAGに読み込ませ、従業員からの問い合わせにAIが自動回答します。「有給の申請方法は?」「経費精算の締め日は?」といった定型的な質問の70〜80%を自動化できたという報告も多いです。
事例2:カスタマーサポートの品質向上
製品FAQやトラブルシューティングガイドをRAGに格納し、顧客対応チャットボットとして活用。オペレーターの負担を軽減しながら、24時間365日の対応を実現します。とくにECサイトや中小企業のカスタマーサポートで導入が加速しています。
事例3:営業支援(商品提案の自動生成)
商品カタログ、過去の提案書、顧客の購買履歴をRAGに読み込ませ、「この顧客にはどの商品を提案すべきか?」をAIが分析。営業担当者の経験やカンに頼らない、データドリブンな商談準備が可能になります。
事例4:法務・コンプライアンスチェック
契約書テンプレート、社内規程、業界ガイドラインをRAGに格納。新しい契約書のドラフトについて「この条項はリスクがないか?」とAIに確認できます。法務部門の初期スクリーニング工数を大幅に削減した事例が増えています。
事例5:ナレッジマネジメント(属人化の解消)
長年のベテラン社員の頭の中にしかないノウハウ。これをドキュメント化してRAGに読み込ませれば、組織知として活用できるようになります。「○○さんに聞かないとわからない」が「AIに聞けばわかる」に変わるインパクトは計り知れません。
RAGのメリット・デメリットを正直に解説

メリット
- ハルシネーションの大幅抑制:根拠ベースの回答で信頼性アップ
- 導入コストが比較的安い:ファインチューニングに比べて圧倒的に低コスト
- 情報更新が簡単:ドキュメントの追加・削除だけでAIの知識を更新可能
- セキュリティ面で優位:データを外部に送信せずオンプレミス運用も可能
- 回答の根拠を提示できる:「このマニュアルの3ページ目に基づいて回答しています」が可能
デメリット
- 検索精度に依存する:データベースの設計や前処理の品質が回答精度を左右する
- チャンク設計が難しい:ドキュメントをどう分割するかで結果が大きく変わる
- レスポンスがやや遅い:検索処理が入る分、通常のAI回答より若干のレイテンシーが発生
- データ整備の手間:「ゴミデータからはゴミ回答しか出ない」ため、元データの品質管理が重要
2026年最新トレンド|RAGはどう進化しているのか
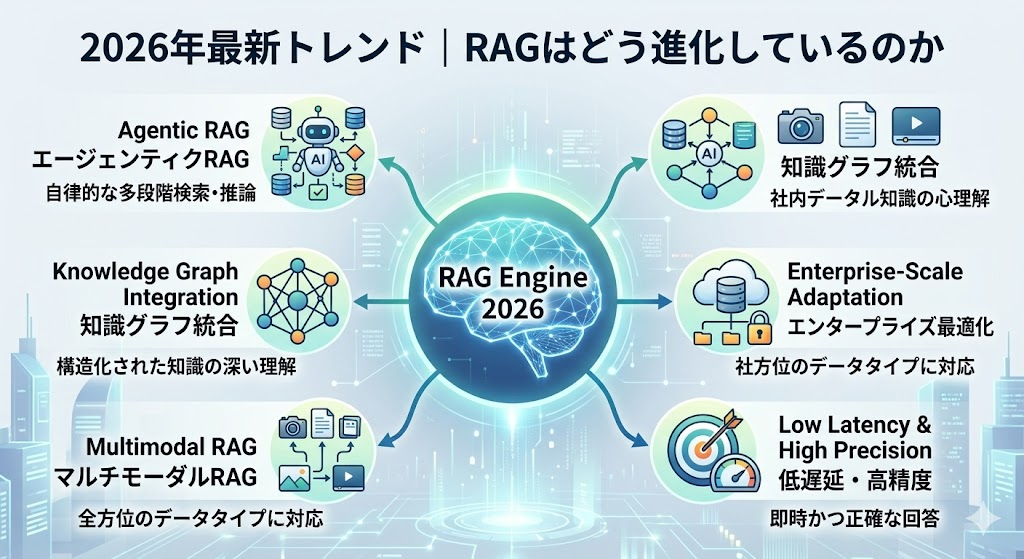
Agentic RAG(エージェンティックRAG)
2026年のRAG界で最もホットなキーワードがこれ。従来のRAGは「質問→検索→回答」の一方通行でしたが、Agentic RAGではAIが自律的に複数回の検索や推論を繰り返し、最適な答えにたどり着きます。
「1回の検索じゃ足りないな…別の角度からも調べよう」とAIが自分で判断するイメージ。業務効率化の文脈では、複雑な問い合わせへの対応精度が飛躍的に向上しています。
GraphRAG(グラフRAG)
従来のベクトル検索に加え、ナレッジグラフ(知識グラフ)を活用する手法。情報と情報の「関連性」を構造化して保持するため、「AとBの関係は?」「Cに影響する要因は?」といった複雑な因果関係を扱う質問に強いのが特徴です。
マルチモーダルRAG
テキストだけでなく、画像・PDF・動画・音声も検索対象にするRAG。たとえば製造業の設備マニュアル(図面付き)をそのまま読み込み、「この部品の交換手順は?」と聞けば図解付きで回答してくれます。
RAGを導入する方法|自社に合ったアプローチを選ぶ
方法1:ノーコードツールで構築する
プログラミング不要でRAGシステムを構築できるツールが増えています。代表的なものがDifyなどのノーコードプラットフォーム。PDFやWordファイルをアップロードするだけで、AIがそのドキュメントを参照して回答するチャットボットを作れます。
非エンジニアでも構築できるため、IT部門のリソースが限られる中小企業に特におすすめのアプローチです。
方法2:クラウドサービスを利用する
Azure OpenAI Service、Amazon Bedrock、Google Vertex AIなどのクラウドサービスは、RAG構築に必要なコンポーネント(ベクトルDB、LLM、検索エンジン)を一括で提供しています。ある程度の技術力がある企業向けですが、スケーラビリティに優れます。
方法3:フルスクラッチで開発する
LangChain、LlamaIndex(旧GPT Index)などのフレームワークを使い、自由度の高いRAGシステムを構築する方法。技術力は必要ですが、チャンク戦略やリランキング、ハイブリッド検索など細かいチューニングが可能です。大規模なデータを扱う企業向け。
RAG導入を成功させる5つのポイント
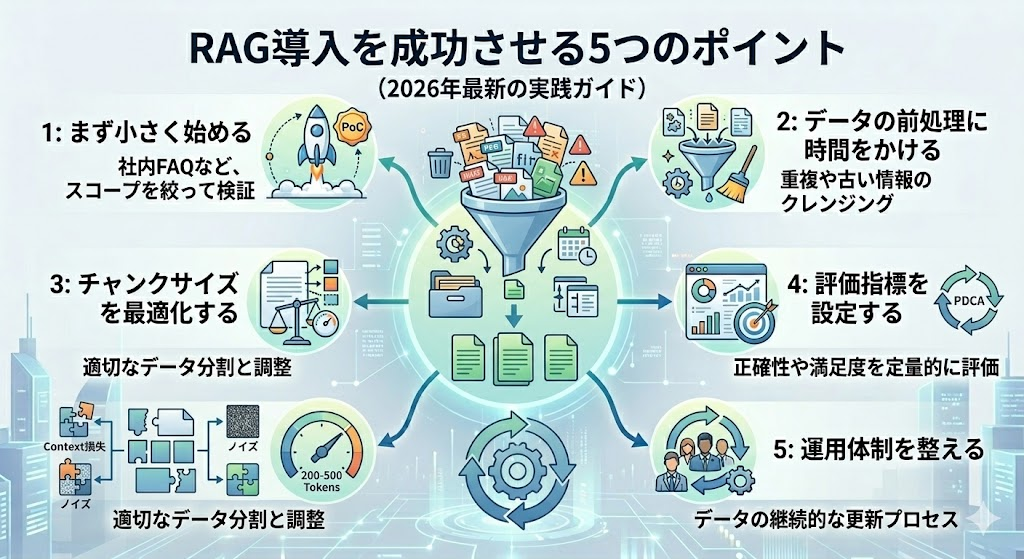
ポイント1:まず小さく始める
いきなり全社データを突っ込もうとすると失敗します。まずは「社内FAQ」や「1つの製品マニュアル」など、スコープを絞って小さくPoCを回すのが鉄則。成功体験を積んでから段階的に拡張しましょう。
ポイント2:データの前処理に時間をかける
RAGの回答精度は、元データの品質で9割決まると言っても過言ではありません。古い情報、重複したドキュメント、フォーマットが統一されていないファイル──これらを事前にクリーニングする工程を絶対にスキップしないでください。
ポイント3:チャンクサイズを最適化する
ドキュメントを細切れ(チャンク)にしてデータベースに格納しますが、このサイズ設定が重要。小さすぎると文脈が失われ、大きすぎるとノイズが増えます。一般的には200〜500トークン程度がスタートラインですが、データの性質によって最適値は変わります。
ポイント4:評価指標を設定する
「なんとなく良くなった気がする」では改善が進みません。回答の正確性、関連性、ユーザー満足度など、定量的な評価指標を設けてPDCAを回しましょう。
ポイント5:運用体制を整える
RAGは「作って終わり」ではありません。データの追加・更新・削除を誰がどのタイミングで行うのか、運用フローを最初から設計しておくことが長期的な成功の鍵です。
RAG導入にかかるコスト感
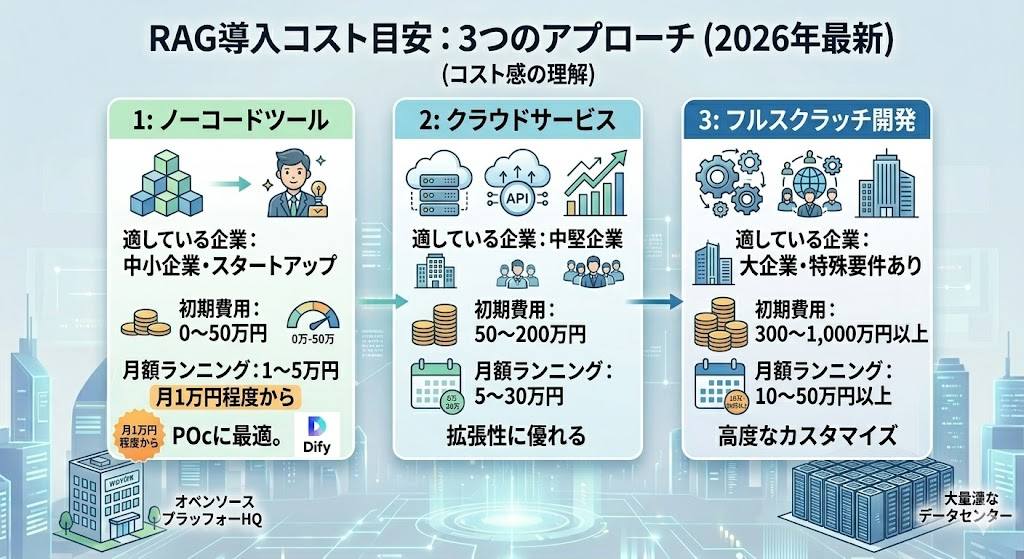
「で、いくらかかるの?」が一番気になるところですよね。ざっくりした目安をお伝えします。
| アプローチ | 初期費用 | 月額ランニング | 向いている企業 |
|---|---|---|---|
| ノーコードツール | 0〜50万円 | 1〜5万円 | 中小企業・スタートアップ |
| クラウドサービス | 50〜200万円 | 5〜30万円 | 中堅企業 |
| フルスクラッチ開発 | 300〜1,000万円以上 | 10〜50万円以上 | 大企業・特殊要件あり |
ノーコードツールを使えば、月1万円程度から始められるのが2026年現在の相場感。「まずは試してみたい」という企業には、Difyのようなオープンソースのプラットフォームを活用すれば、ほぼゼロコストでPoCが可能です。
よくある質問(FAQ)
Q. RAGを使えばハルシネーションは完全になくなりますか?
A. 残念ながら「完全にゼロ」にはなりません。ただし、適切に構築すれば体感で80〜90%は改善します。特に、参照データが存在しない質問に対しては「わかりません」と答えるよう設定することで、嘘の回答を防げます。
Q. どのくらいのデータ量から効果が出ますか?
A. 数十ページのFAQやマニュアルからでも十分効果が実感できます。データが多いほど有利ですが、「量より質」が原則。整理された少量のデータのほうが、乱雑な大量データよりも良い回答を生み出します。
Q. セキュリティは大丈夫?社外にデータが漏れない?
A. RAGの構成次第です。オンプレミスでLLMを動かし、ベクトルDBも社内に置けば、データは一切外部に出ません。クラウドサービスを使う場合も、多くのサービスがデータの暗号化とリージョン指定に対応しています。
Q. 対応できるファイル形式は?
A. 一般的なRAGシステムでは、PDF、Word、Excel、PowerPoint、テキストファイル、HTML、Markdownなどに対応しています。ツールによっては画像(OCR)や音声(文字起こし)にも対応可能です。
まとめ|RAGは「使えるAI」への最短ルート
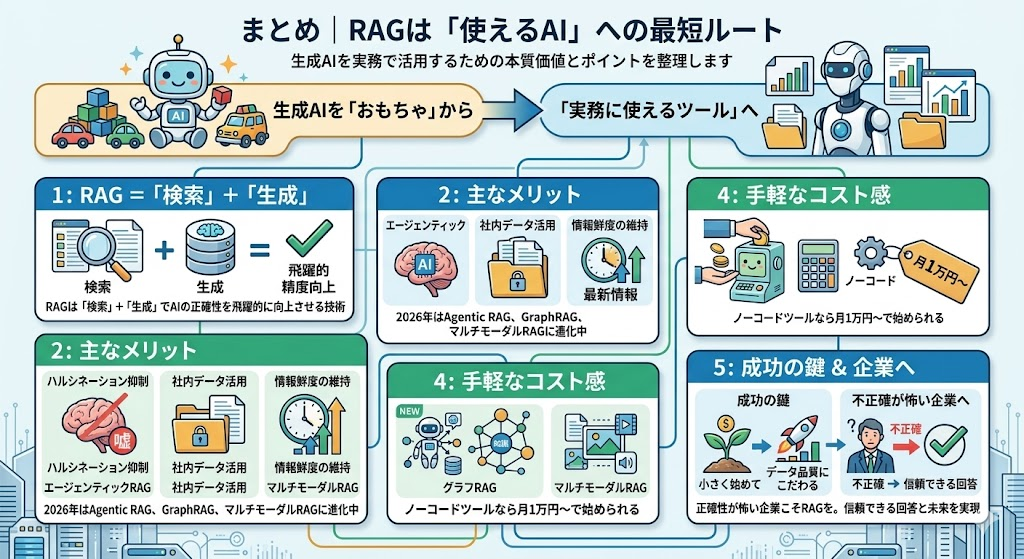
生成AIを「おもちゃ」から「実務に使えるツール」に変える──それがRAGの本質的な価値です。
もう一度ポイントを整理すると:
- RAGは「検索」+「生成」でAIの正確性を飛躍的に向上させる技術
- ハルシネーション抑制、社内データ活用、情報鮮度の維持が主なメリット
- 2026年はAgentic RAG、GraphRAG、マルチモーダルRAGに進化中
- ノーコードツールなら月1万円〜で始められる
- 成功の鍵は「小さく始めて、データ品質にこだわる」こと
「AI導入に興味はあるけど、正確じゃないのが怖い…」という企業こそ、RAGを検討すべきです。正しい情報に基づいた、信頼できるAI回答。それがRAGで実現する未来です。
AIチャットボットの導入を検討中の方へ
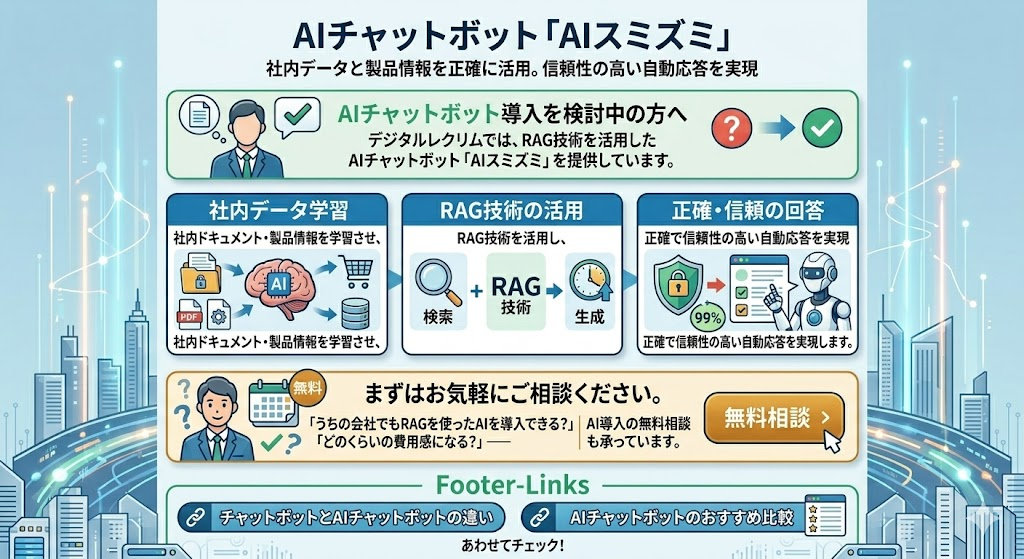
デジタルレクリムでは、RAG技術を活用したAIチャットボット「AIスミズミ」を提供しています。御社の社内ドキュメントや製品情報を学習させ、正確で信頼性の高い自動応答を実現します。
「うちの会社でもRAGを使ったAIを導入できる?」「どのくらいの費用感になる?」──まずはお気軽にご相談ください。AI導入の無料相談も承っています。
また、チャットボットとAIチャットボットの違いや、AIチャットボットのおすすめ比較もあわせてチェックしてみてください。
参考記事:最先端のGraphRAGの技術をDifyに落とし込み、最高精度なRAGを構築する


コメント