
近年、人工知能(AI)の急速な進化に伴い、LLM(大規模言語モデル)が注目を集めています。LLMとは何か、そしてなぜこれほどの関心を集めているのか、気になっている方も多いのではないでしょうか。
LLMは、大量のテキストデータを学習し、人間に近い自然な言語理解と生成を実現するAIの中核技術です。幅広い応用分野があり、文章作成、要約、翻訳、対話システムなど、多様な場面で活躍しています。
しかし、その仕組みや種類、最先端の活用法、さらには安全性や倫理的な課題まで、知っておきたい情報は幅広く存在します。特に、「llmとは ai」として検索されるように、AI技術の基本として理解することが今後ますます重要になるでしょう。
この記事では、LLMの基礎知識から種類、プロンプトエンジニアリング、ファインチューニング、さらにはローカル環境での活用や最新のRAGモデルまで、幅広く詳しく解説していきます。初心者の方でも理解しやすいよう専門用語の丁寧な説明を加えつつ、多様な事例を紹介し、ご自身での活用や企業導入の参考になる内容を目指しました。
例えば、LLMをより効果的に運用するための「プロンプトエンジニアリング」や、特定の業務に適したモデルにカスタマイズする「ファインチューニング」といった応用的な技術もわかりやすく解説します。加えて、ローカル環境でのLLM運用のメリット・デメリットや、新しい技術として注目される「RAG(Retrieval-Augmented Generation)」モデルの役割にも触れています。
これらの内容は、AI導入を検討している企業や、最新のAI技術の動向を追いたい技術者、研究者の皆様にとっても貴重な情報源になるはずです。変化の速いAI分野において正確かつ信頼できる情報を得ることは、適切な技術選択と効率的な運用につながります。
さらに、LLM技術の安全性や倫理的な側面にも着目し、AIが社会に与えるインパクトを冷静に見つめる視点も提供します。今後の技術進化に伴うリスク管理や規制の動向は、利用者・開発者双方にとって欠かせない課題です。
このページでは、信頼できる情報源や業界の最新動向を踏まえつつ、わかりやすく丁寧にLLMを解説しています。「LLMとは何か?」を知り、AI時代の最先端技術を理解する第一歩として、ぜひご活用ください。
なお、関連する技術や応用例については当サイトの【2025年版】AI導入を検討中の企業必見!東京の注目AI開発会社とサービス徹底比較もぜひ参照してみてください。AI導入を具体的に考える上で、最新の開発会社動向やサービス比較情報が役立ちます。
LLMの種類とその違い
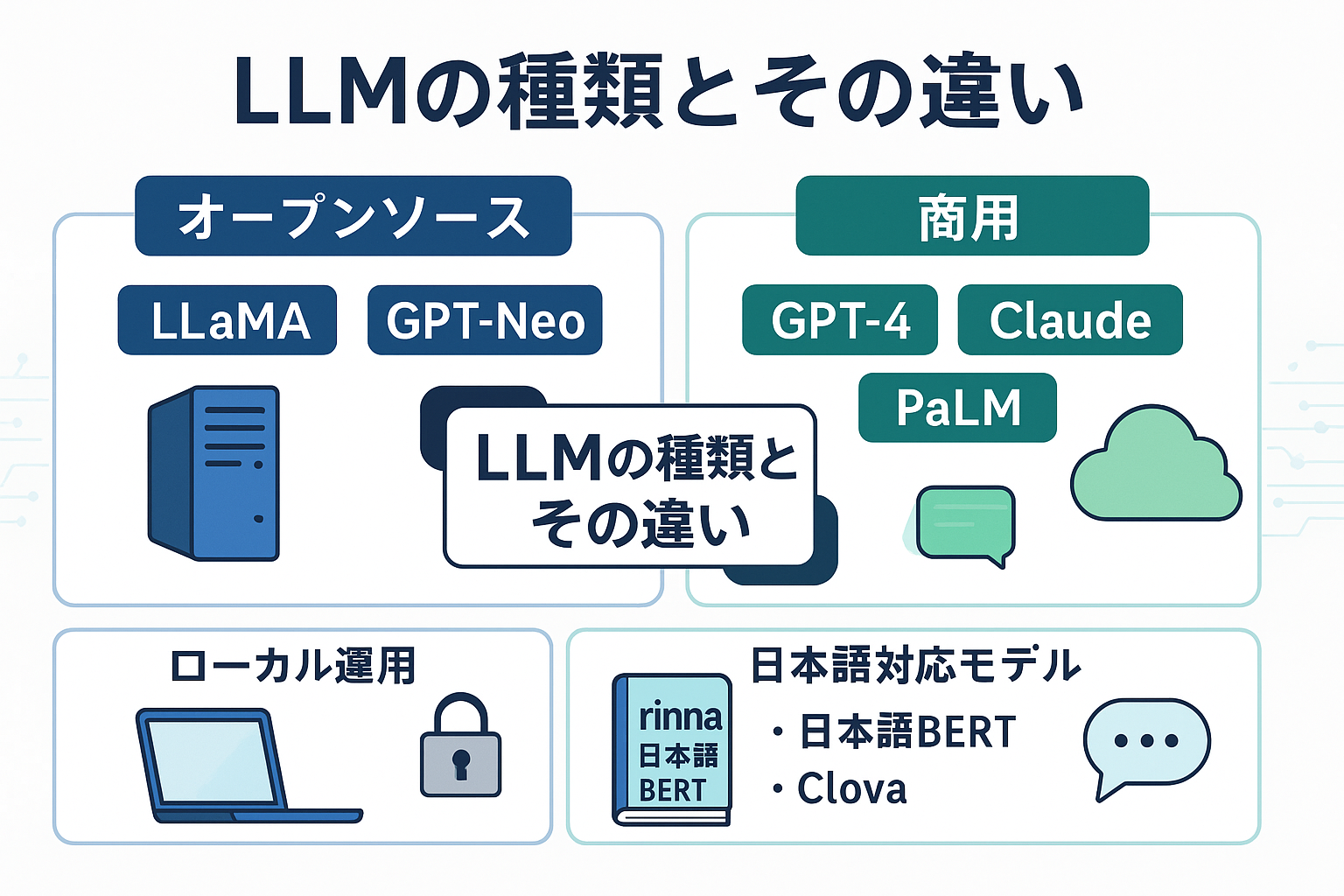
LLM(大規模言語モデル)は、AI技術の進化とともに多様な種類が登場し、それぞれが異なる特徴や用途を持っています。このセクションでは、「llm 種類」に焦点を当て、代表的なオープンソースLLMと商用LLMの違いをわかりやすく解説します。また、日本語対応モデルの現状についても詳述し、さらに「llm ローカル」運用のメリット・デメリットをバランス良く紹介します。これにより、皆様が目的や環境に応じた最適な言語モデル選択の参考にしていただけます。
オープンソースLLMと商用LLMの比較
まず、LLMの代表的な種類として「オープンソースLLM」と「商用LLM」があります。オープンソースLLMは無償で公開され、カスタマイズやローカル運用が可能なモデル群です。代表例には、Metaが開発した「LLaMA」や、EleutherAIの「GPT-Neo」シリーズなどが含まれます。一方で、商用LLMは企業によって提供されるクラウドベースのサービスが中心で、OpenAIの「GPT-4」、Googleの「PaLM」、Anthropicの「Claude」などが該当します。
両者の大きな違いは利用形態とコスト面です。オープンソースLLMは自由度が高く、研究開発や特定のニーズに合わせた改良が可能です。例えば、企業が自社のデータに特化してファインチューニングし、内部システムに組み込むケースが増えています。ただし、運用には高い計算リソースや専門知識が求められ、導入から維持管理までのコストと労力がかかる点が課題です。
これに対し、商用LLMは即座に利用できる利便性と安定した性能が魅力です。API連携を通じて簡単にサービスに組み込め、メンテナンスやモデルのアップデートも提供側に任せられます。例えば、カスタマーサポートのチャットボットやコンテンツ生成など多様な業務で活用されており、運用負担の軽減が期待されます。一方で、使用料やAPIコールの単価が継続的に発生するため、中長期的なコスト計算が必要です。
また、データのプライバシー面も選択基準の一つです。オープンソースモデルをローカル環境で運用すれば、社内の機密情報を外部に出さずに処理できるメリットがあります。商用LLMでは外部クラウドに機密データを送信するため、セキュリティポリシーに準拠した運用が重要となります。こうした点を踏まえ、利用者のニーズやリソースに応じた選択が求められます。
日本語対応モデルの現状と特徴
LLMの多くは英語を中心に開発が進められてきましたが、日本語対応のニーズが高まる中で国内外の企業や研究機関が独自の日本語モデルや多言語モデルを提供しています。日本語は文法構造や語彙の特徴が英語と大きく異なるため、単純な英語モデルの翻訳利用では性能が限定的になることがあります。
代表的な日本語対応モデルには、東北大学とPreferred Networksが開発した「rinna」のモデル群や、国立情報学研究所が公開する「日本語BERT」系列、さらに商用ではLINEの「Clova AI」シリーズなどがあります。これらは膨大な日本語コーパスで学習されており、形態素解析や文脈理解の精度が高い点が特長です。
日本語対応のLLMを選定する場合、モデルのトレーニングデータやアーキテクチャに注目しましょう。多言語対応型のモデルは多様な言語に対応しますが、日本語特有のニュアンスを捉えるには専用にチューニングされたモデルのほうが有利です。たとえば、日本語の敬語表現や同音異義語の区別などが正確に反映されると、カスタマーサポートや自動要約、コンテンツ生成での品質が向上します。
加えて、日本語特有の課題として「大文字・小文字」の概念が少ないことや漢字・ひらがな・カタカナの混在が挙げられます。これに対応したトークナイザー(単語分割器)の設計が重要です。近年ではDeepLやGoogle翻訳などの商用サービスも含め、日本語処理能力の向上に多くの注力がなされています。
日本語対応モデルの性能向上は国内ビジネスに大きな影響を与えており、文章生成や要約、意図理解、対話システムでの活用が急増しています。AIチャットボットや自動文書作成、教育支援アプリなど、多彩なサービス開発に貢献していることも特筆すべきポイントです。
llm ローカル運用のメリット・デメリット
近年、llm ローカル運用への関心が高まっています。これは、LLMを自社や個人の環境にインストールして、外部クラウドを介さずに利用する形態です。ローカル運用は特にプライバシー保護やレスポンス速度、コスト管理上のメリットがある一方で、それに伴う技術的・運用面のデメリットも理解しておく必要があります。
メリットの一つ目は、データの安全性が高まることです。企業が機密情報を扱う場合、外部サーバーに送信しないことで漏洩リスクを最小限に抑えられます。医療機関や金融機関など高度な情報管理が求められる業界で特に支持されています。
二つ目は、通信環境に依存しない高速な処理が可能な点です。ローカルに十分なGPUやTPUがある場合、APIの待機時間やネットワーク遅延がなくなり、リアルタイムの対話システムやバッチ処理での利便性が向上します。
さらに三つ目は長期的なコスト削減です。クラウドAPIの利用料が積み重なると高額になる場合、初期投資と維持管理が可能であればローカル運用のほうが経済的です。特に大規模なデータ処理や大量リクエストが想定されるケースで効果的です。
一方で、ローカル運用には技術的な課題も存在します。高度なハードウェアが必要であり、モデルのダウンロードやセットアップ、メンテナンスを行うための専門知識が不可欠です。最新のアップデートやパッチ適用は自己責任となり、これが運用コスト増につながることもあります。
また、リソース消費が激しい問題も無視できません。大規模なLLMは膨大なメモリやストレージを必要とし、推論時の計算負荷も高いため、一般的なPCやサーバーでは動作が難しいことがあります。軽量化モデルや蒸留技術の活用が解決策として注目されていますが、性能とのトレードオフを考慮しなければなりません。
さらに、モデルの更新や改善も制限されるため、商用サービスが提供する最新機能や安全性強化策をすぐに享受できません。さらには、法令順守やセキュリティ監査の対応も独自に行う必要があり、運用管理が複雑化します。
以上のように、「llm ローカル」運用は強力な選択肢である一方、導入前にメリット・デメリットを総合的に判断し、目的やリソースにマッチした運用計画を立てることが成功の鍵となります。
LLMのプロンプトエンジニアリング入門
LLMを活用する上で不可欠な技術・スキルに「llmのプロンプトエンジニアリング」があります。これは、モデルに対して適切な問いかけ(プロンプト)を設計し、望む回答や生成結果を引き出す技術のことです。本章では、プロンプトエンジニアリングの基本概念から実用的な設計法まで、さらに最新技術の一つであるRAG(Retrieval-Augmented Generation)との関係性も含めて具体的に紹介します。プロンプト設計の理解を深め、効果的なLLM活用を目指しましょう。
プロンプトエンジニアリングとは?基本概念
プロンプトエンジニアリングはLLMの性能を最大限に引き出すための「問いの作り方」を指します。LLMは与えられたテキストに基づいて応答を生成しますが、プロンプトの内容や構造が不適切だと、意図しない回答や誤情報が出力されることもあります。
そのため、単に質問を投げかけるのではなく、文脈を与えたり、条件を明確に示したり、形式的な指示を工夫したりと、プロンプトの工夫が成果を左右します。たとえば、同じ内容でも指示文を少し変えるだけで、回答の詳細レベルや文章のトーン、情報の正確性が大きく変化するケースが多々あります。
具体例を挙げると、「猫について教えてください」という曖昧なプロンプトに対し、「初心者向けに、猫の飼育方法を3つのポイントでわかりやすく説明してください」という風に条件を追加すると、より実用的な回答が得られます。このように、目的に応じてプロンプトを設計することがプロンプトエンジニアリングの本質です。
実用的なプロンプト設計法と成功例
効果的なプロンプト設計における代表的なテクニックには、以下があります。
- 具体的で詳細な指示を含める:「何を」「どのように」「どの範囲で」を明確にし、曖昧さを排除します。
- 条件や制約を追加する:文字数制限、トーンの設定(例:カジュアル、ビジネス)、段階的な説明などを指定します。
- 例示を加える:望む回答例を前もって示すことで、モデルの出力を誘導します。
- 段階的指示を与える:大規模かつ複雑なタスクは、小さなステップに分けて依頼すると成功率が向上します。
- 複数の質問を組み合わせる:一つのプロンプトで多様な視点を引き出す工夫を行います。
実務例では、企業のカスタマーサポートチャットボットの構築において、ユーザーの問い合わせ内容に応じて最適な回答を生成しています。プロンプトを段階的に設計し、FAQ形式の質問・回答を組み込むことで、誤回答率の低減や応対速度の向上が確認されています。
また、クリエイティブな文章作成では、作風やジャンル、使用言語スタイルに基づくプロンプト設計が重要となり、成功事例が多数報告されています。これらの具体的技術は、業務効率化やコンテンツ品質向上に繋がっています。
RAG(Retrieval-Augmented Generation)とプロンプトの関係性
RAG(Retrieval-Augmented Generation)は、外部の情報検索(Retrieval)とLLMのテキスト生成(Generation)を組み合わせた先進的なアプローチです。RAGモデルは必要に応じて大量の知識ベースやドキュメントから関連情報をリアルタイムに取得し、それを補完する形で回答を生成します。
この仕組みは、固定された静的なプロンプトだけではカバーできない最新情報やドメイン固有知識の活用を可能にします。つまり、プロンプトは単なる「問い」から、動的に外部情報を組み込むための「インターフェース」として機能します。
具体例として、法務分野の質問応答システムでは、法律データベースから関連条文を検索しつつ、LLMが文脈に沿った分かりやすい説明文を生成します。このとき、プロンプト設計は検索結果の要約やどの情報を活用すべきかを指示する重要な役割を担います。
RAGによってプロンプトの役割は従来以上に高度化し、AIの応答品質や信頼性が飛躍的に向上しています。このため、「llm rag」の活用は今後ますます注目され、プロンプトエンジニアリングの重要な要素となるでしょう。
LLMのファインチューニング技術と応用ケーススタディ
LLMのファインチューニングは、既存の大規模言語モデルを特定の目的やデータセットに適応させる技術です。このセクションではファインチューニングの基礎から最新手法までを掘り下げ、さらに実際の業界での応用例を具体的に紹介します。ファインチューニングは、モデルの汎用性を高める一方で、専門領域での精度向上を実現するため、AI活用の重要なステップと言えます。
ファインチューニングの基礎とその目的
ファインチューニングは、大規模言語モデルのプレトレーニング済みパラメータを調整し、特定のタスクやドメインに特化させる手法です。基本的には、大量の一般テキストデータを用いた「事前学習(プリトレーニング)」の後、専門的なデータセットでさらに学習を進めることで精度を改善します。
たとえば、医療分野で診断支援を行いたい場合、一般的な文章理解に加えて医学論文や患者記録に特化したデータセットを用いてファインチューニングが施されます。これにより、モデルは医療用語や専門知識を深く理解し、より適切な回答が可能となるのです。
この技術の目的は多岐にわたり、以下のような課題解決に貢献します。
- 特定業界の専門用語や表現への対応性の向上
- 一般モデルが苦手とする細かいニュアンスや文脈理解の強化
- カスタマイズによる業務効率化と誤情報の低減
また、ファインチューニングは単に精度を上げるだけでなく、モデルのサイズやパフォーマンスのトレードオフを調整することも含まれます。これにより、実運用環境の制約にあった最適化も可能となります。
最新のファインチューニング手法とツール
従来のファインチューニングは全パラメータを再学習するため膨大な計算資源が必要でしたが、近年では効率性を重視した新たな手法が台頭しています。代表的な手法には以下のものがあります。
- LoRA(Low-Rank Adaptation): モデルのパラメータのうち低ランクな部分のみを追加学習することで、ファインチューニングの計算コストを大幅に削減します。これにより、従来の10分の1程度のリソースで済むケースもあります。
- PEFT(Parameter-Efficient Fine-Tuning): パラメータ効率的チューニングの総称で、小規模な変更のみで性能を維持しながら調整可能。具体的には、追加層の挿入やモジュール単位の微調整を行います。
- Adapter Modules: 元のモデルのパラメータを固定し、新たな層を組み込むことで追加学習を実施。モデルの安定性を保ちつつ、多様なタスクに柔軟に対応可能です。
こうした手法の登場により、中小企業や研究機関など計算リソースが限られた環境でもファインチューニングを実践しやすくなりました。オープンソースツールとしては、Hugging FaceのTransformersライブラリがLoRAやAdapterの実装をサポートしています。
加えて、GoogleやOpenAIが提供するAPIサービスでも「カスタムファインチューニング」機能が拡充され、初心者でも高性能なモデルの特化調整が行えるようになりました。こうしたツール群はエンジニアリングの敷居を下げ、大規模モデルの実務適用を加速させています。
具体的な業界別応用事例(医療、教育、カスタマーサポート)
ファインチューニングの具体的な効果が顕著に現れている業界事例を3例紹介します。
1. 医療領域: ある製薬企業は、汎用LLMを医療文献と患者レポートに特化したファインチューニングにより、新薬の副作用分析や診断支援システムを高度化しました。患者の質問に対して、専門的ながらもわかりやすい回答を自動生成し、医療スタッフの負担軽減に成功しています。
2. 教育分野: オンライン教育プラットフォームが学生の言語活動サポートに特化したファインチューニングを実施。具体的には、児童向けの語彙や表現、解説スタイルに合わせた微調整を加えることで、AIチューターの応答精度が飛躍的に向上しました。発展的な質問にも対応可能となり、学習効率が高まっています。
3. カスタマーサポート: 通信業界のカスタマーサポートチャットボットは、ユーザー問い合わせデータを用いたファインチューニングを活用。業界特有の問い合わせパターンや商品仕様を学習し、解決率を大幅に改善。通常のFAQ対応から複雑な問題の初期対応まで幅広くカバーしています。
これらの事例に共通するのは、ファインチューニングを行うことでLLMの汎用的な知識を専門領域の実務知識へ転換できる点です。結果として、業務効率化はもちろん、ユーザー満足度の向上やコスト削減にも寄与しています。
LLMの未来と課題:安全性・倫理・最新動向
次に、LLM技術の成長を支える持続可能性を確保するための安全性や倫理的観点、そして将来的な動向を念頭に置いてお話しします。急速な進化を続ける技術だけに、リスク管理や社会的受容が重要になっています。
LLM関連の安全対策とリスク管理
LLMの活用拡大に伴い、安全性の確保は最優先課題となっています。主なリスクとしては、誤情報の生成(フェイクニュース)、差別的・偏見的な発言、プライバシー侵害の恐れ、不適切コンテンツの生成などが挙げられます。
これらを防ぐために、多層的な対策が講じられています。具体例として、以下の方法が現場で実装されています。
- 出力フィルタリング: 悪意や不適切表現を検知するブラックリスト・ホワイトリスト方式、コンテンツスキャン技術の導入
- 利用者モデレーション: AIの回答内容を人間がチェックし、問題を早期に発見・修正する体制の整備
- 学習データの適正化: バイアスや不適切情報を含まないように、データクリーニングや多様なソースの活用を推進
- アクセス制御とロギング: 利用者やアクセスの監視を行い、不正利用や悪用を抑制
また、ファインチューニング時にバイアスが入り込まないよう、繰り返し評価とテストを実施することも安全対策の要です。これにより、より信頼性の高いLLM運用が可能になります。
AI倫理におけるLLMの位置付け
LLMの倫理問題は、技術開発者だけでなく社会全体の関心事です。特に、透明性、説明責任、公平性、プライバシー保護に焦点が当てられています。
例えば、ブラックボックス化しやすい大規模モデルの判断過程を明確にする取り組みが進んでいます。こうした「説明可能AI(Explainable AI)」は、LLMがどのように結論に至ったかを理解しやすくし、誤用を防ぐ効果があります。
さらに、LLMによる差別的結果を避けるため、多様なデータセットでトレーニングをしたり、倫理委員会がガイドラインを制定したりする企業や団体が増加中です。ユーザーのプライバシーを尊重しつつ、安全で公正なAI活用を目指すことが求められています。
今後の技術進化と市場動向予測
今後のLLM技術は、より高度なパーソナライゼーションとリアルタイム学習能力の獲得が期待されています。ユーザーの行動や環境に応じて動的に適応し、より人間らしい対話や専門的支援を提供することが目標です。
また、マルチモーダルAIの進展により、テキストだけでなく画像や音声、動画など複数の情報を統合して処理できるモデルとしてLLMは進化します。これにより、医療画像診断支援や教育現場での実践的応用が飛躍的に広がるでしょう。
市場面では、オープンソースモデルと商用モデルの競争が激化すると考えられています。特にデータプライバシー重視の観点から、ローカル環境でのファインチューニングや推論実行が企業でますます増加。加えて、自治体や官公庁におけるAI活用促進政策も追い風となっています。
AI倫理に関する法整備も進む中、テクノロジーの安全・公正利用を担保しながら、市場全体が成熟期に向かっていく流れが鮮明になっています。こうした最新動向を押さえることが、今後のLLMを適切に運用する鍵となるでしょう。
LLM理解を深め、未来の活用に備えるための重要ポイント

LLM(大規模言語モデル)は、AI技術の中核を成す革新的な存在であり、言語理解や生成において人間に近い精度を実現しています。この記事で解説したように、LLMとは単なる技術用語ではなく、トランスフォーマーアーキテクチャやニューラルネットワークといった高度な仕組みに基づき、膨大なデータから学習して自然言語処理の精度を引き上げる仕組みです。その基本を理解することで、AI時代における技術の全体像や可能性を掴むことができます。
複数のLLMの種類について比較検討すると、オープンソースモデルと商用モデルで機能や利用環境・対応言語に差があることが分かります。例えば、オープンソースLLMは無料でカスタマイズ可能ですが、ローカル環境で運用する場合は高い計算リソースや管理ノウハウが必要です。一方、商用LLMは導入の手軽さや安定性が強みですが、利用コストやデータプライバシーの観点で検討が欠かせません。こうした特徴を踏まえて、自社のニーズに適したモデル選択が重要です。
また、LLMのパフォーマンスを最大限に引き出すにはプロンプトエンジニアリングの技術が欠かせません。適切なプロンプト設計を行うことで、生成される文章の質や回答の的確さが大きく向上し、業務効率化やサービス改善に直結します。RAG(Retrieval-Augmented Generation)モデルの活用も含め、情報検索と生成を組み合わせたハイブリッドアプローチは、特に大量の外部知識を必要とする場面で強力な武器となります。
さらに、ファインチューニングはLLMを特定の業務用途や業界に特化させるための有効な手法です。医療や教育、カスタマーサポートなど、各分野で成功事例が増加しており、企業は自社の課題や目的に応じてモデルの微調整を検討するべきです。ファインチューニングには適切なデータ準備と技術的知見が求められますが、効果的に実施すれば既存の言語モデルを飛躍的に性能向上させることが可能です。
一方で、LLMの導入に際しては安全性や倫理の問題も無視できません。不正確な情報の生成リスクや偏見の存在、プライバシーの保護など、AI倫理の視点から慎重に運用する必要があります。最新の技術動向や規制情報を常に確認し、安全対策を講じながらLLMのメリットを最大限に活用していくことが求められています。
これらの理解を踏まえると、LLMの知識は単なる技術的な知見に留まらず、ビジネスや社会の変革を支える戦略的資産として位置づけられるでしょう。現代のデジタルトランスフォーメーションにおいて、AI技術の理解と活用は競争力の鍵であり、LLMはその中心的な役割を果たします。
今後、皆様がLLMを効果的に取り入れるためには、まず自社の業務課題や目標を明確にし、適切なモデルの選定と運用体制の構築に着手することが重要です。例えば、ローカル環境にLLMを導入して高いセキュリティを確保するのか、商用クラウドサービスを活用してスケーラブルな展開を目指すのかは、コストやリスク評価と合わせて検討しましょう。
また、プロンプトエンジニアリングやファインチューニングのスキルを内部で育成・強化し、データの質や適切な管理体制を備えることが成功のカギとなります。これらの技術は日進月歩で進化しているため、最新の情報収集や専門家との連携も忘れずに行うべきです。
最後に、LLM活用の第一歩を踏み出す際には、初学者向けの講座や資料、オンラインコミュニティへの参加が大いに役立ちます。深く学べる専門書籍やウェビナー、プログラミング実践の場を活用し、段階的に理解を深めていくことをおすすめします。
総じて、LLMはAI時代の言語処理技術の最前線に位置しており、その理解と活用はこれからのビジネスや研究の可能性を大きく広げるでしょう。焦らず基礎から応用まで着実にマスターし、未来を見据えた技術戦略を構築してください。


コメント